[日本語まとめ] Manipulator-Independent Representations for Visual Imitation
Yuxiang Zhou, Yusuf Aytar, Konstantinos Bousmalis
どんなもの?
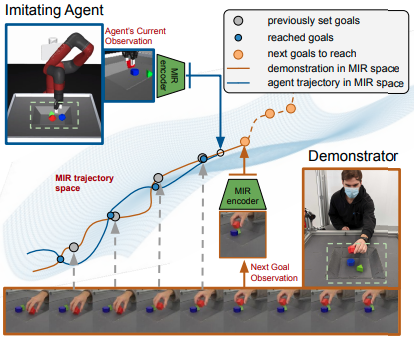
人や違う形態のロボットのデモンストレーション動画から、エージェントが自身のマニピュレータを操作してデモストレーションと同じタスクを解く方法を提案する。エージェントと異なる形態を持つデモストレーションを元に方策を学習する場合、デモストレーションとエージェントのドメインが異なることが問題となる。提案手法はこの違いを解消するため、観測をどんなマニピュレータのどんなタスクにも使える表現(MIR=Manipulator-Independent Representations)への埋め込みを行う。埋め込み後はデモストレーションとエージェントの観測が同一のMIR空間で表現される。したがってMIR空間上でデモンストレーションをエージェントが到達するべきゴールとして設定し、強化学習を行うことでタスクを解く方策を訓練することができる。この学習方法をCross-embodiment Imitationと呼ぶ。
先行研究と比べてどこがすごい?何を解決したか?
強化学習の報酬設計や環境の探索が難しいとき、模倣学習は有効な手段である。behavior cloningや逆強化学習などの模倣手法は一人称の行動と状態で構成されるデータから方策を求める。しかしながら、人間や他の動物が動作を真似る方法は明らかにこれらの模倣学習と違う。これを動機づけとして、エキスパートがどう動いたかの行動にアクセスすることなく異なるドメインのエキスパートの視覚情報のみから模倣する方法を提案する。MIRは未知な形態のマニピュレータのデモンストレーションから学ぶことができる。
手法は?
Cross-embodiment Imitation via RL
Cross-embodiment Imitationは図に示すようにMIR空間で強化学習を繰り返す方法である。MIR空間にエンコードするMIRエンコーダを使って、ロボットのカメラ画像\(o\)およびデモンストレーション動画内から選ばれた1つのフレーム\(\bar{g}\)をエンコードする。エンコードされたカメラ画像\(\phi(o)\)を状態、デモンストレーション画像\(\phi(\bar{g})\)をゴールとみなす。エージェントは状態とゴールを受け取り、5自由度のロボットを操作する。強化学習の一つであるMaximum a Posteriori Policy Optimization (MPO)を使って状態をゴールに到達させるエージェントの方策を求める。エージェントがゴールに到達するたびに新しいゴールをデモストレーションから選んで再度方策の学習を行う。ゴールの候補は5~10フレーム後の画像である。
ゴール到達時の報酬関数は次のように与えられる。
\[\newcommand{\if}{\mathop{\mathrm{if}}\nolimits} \newcommand{\otherwise}{\mathop{\mathrm{otherwise}}\nolimits} r(o, \bar{g}) = \left\{ \begin{array}{ll} 1, & \if \exp(-w \| \phi(o) - \phi(\bar{g}) \|^2) > \epsilon\\ 0, & \otherwise \end{array} \right.\]\(w\)はデモンストレーションの隣接するフレーム間のユークリッド距離\(d(\phi(o), \phi(\bar{o}))\)の平均である。\(\epsilon\)は[0, 1]の値をとる閾値であり、チューニングした結果0.3である。
以下ではMIR空間の学習方法について示す。
MIR空間の学習
MIR空間の学習のためマニピュレータに関するドメインランダマイゼーションを行う。シミュレーション環境でロボットを操作してタスクを行い、その操作軌跡を2つの方法で観測する。同一シーンに対する観測のペア\(\mathbf{o} = {o_i}_{i=1}^N\)、\(\bar{\mathbf{o}} = {\bar{o}_i}_{i=1}^N\)、および行動\(\mathbf{a} = {a_i}_{i=1}^N\)を取得する。
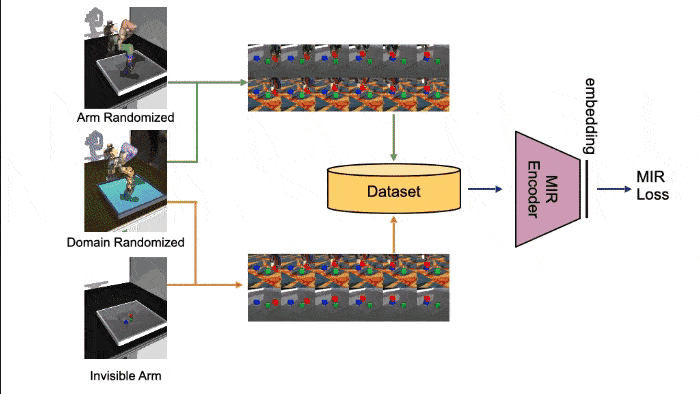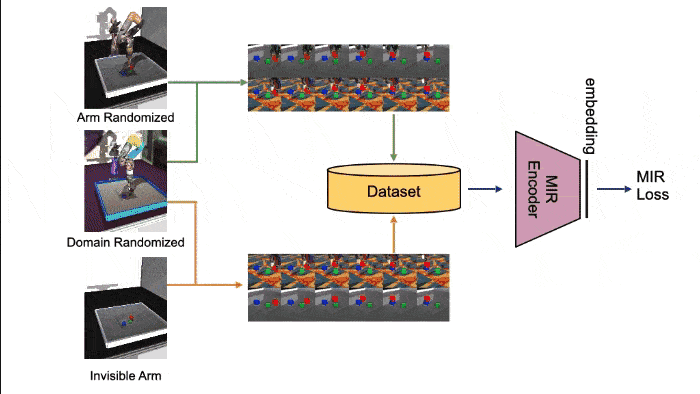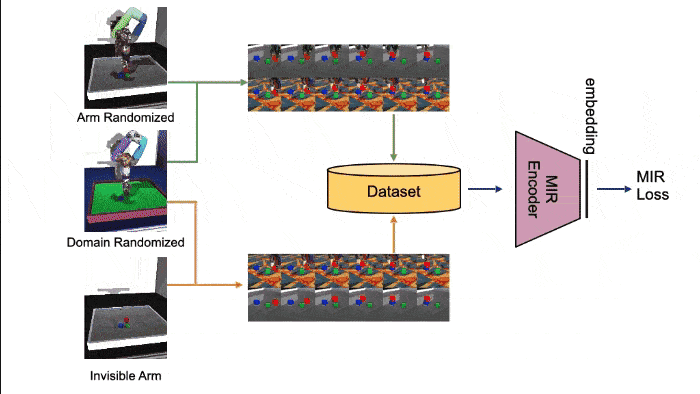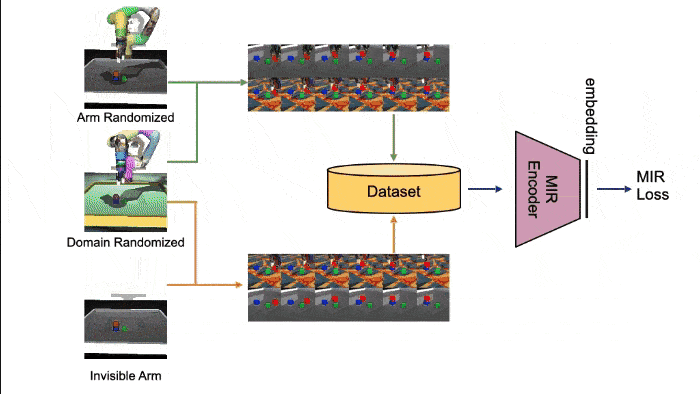
訓練データを収集した後、画像\(o\)を受け取りMIR空間にマッピングするMIRエンコーダ\(x = \phi(o)\)を次の2つの方法で訓練する。
- Temporally-Smooth Contrastive Networks (TSCN)
- Cross-Domain Goal-Conditional Policies (CD-GCP)
この2つの方法で学習することでマニピュレータの動きを捉えたまま、様々なドメインの観測を以下の特性を持つ埋め込み空間(MIR空間)にマッピングすることができる。
- Cross-Domain Alignment 異なるドメインの同一シーンを同じ場所にマッピングする
- Temporal Smoothness 時間的に近いシーンを近くにマッピングする
- Actionable Representations 強化学習に用いるため埋め込みから行動が推論できる
Temporally-Smooth Contrastive Networks (TSCN)
TSCN(Temporally-Smooth Contrastive Networks)は収集した同一シーンを示す観測のペア\((o_i, \bar{o}_i)_{i=1,...,N}\)を使って次のContrastive lossによりの距離学習を行うことにより、埋め込み空間を学習する方法である。
\[\min_{\phi} \left( - \sum_i^{N} \sum_k^{N} p_{ik} \log \frac {\exp(x_i^{T} \bar{x}_k)} {\sum_j^N \exp \left(x_i^T \bar{x}_j \right)} \right)\]ここで\(x = \phi(o)\)、\(\bar{x} = \phi(\bar{o})\)はエンコードされた観測のペアである。\(p_{ik}\)は比べているフレームのインデックスが近いときは小さく、フレームのインデックスが遠いときには大きくなるような重みである。
\[p_{ik} = \frac{\exp (- |i-k|)}{\sum_u^N \exp(-|i-u|)}\]重み\(p_{ik}\)を用いることで隣接したペア\((x_i, \bar{x}_{i+1})\)と離れたペア\((x_i, \bar{x}_{i+50})\)の違いを表現し、時間的な滑らかさを考慮することができる。TSCNはTime-Contrastive Networks: Self-Supervised Learning from Video(arxiv)で提案されたTCN(Time-Contrastive Networks)の拡張版である。
Cross-Domain Goal-Conditional Policies (CD-GCP)
CD-GCPは観測から行動を出力する方策\(\pi_{\times} (\phi(o_i), \phi(\bar{o}_{i+j}))\)を訓練することにより、行動に関連付けられた埋め込み空間を学習する方法である。損失関数は次のものを用いる。
\[\| \pi_{\times} (x_i, \bar{x}_{i+j}) - a_i \|^2\]ここで\(1 \le j \le N\)である。実験では\(N=20\)を用いる。
具体的なアーキテクチャ
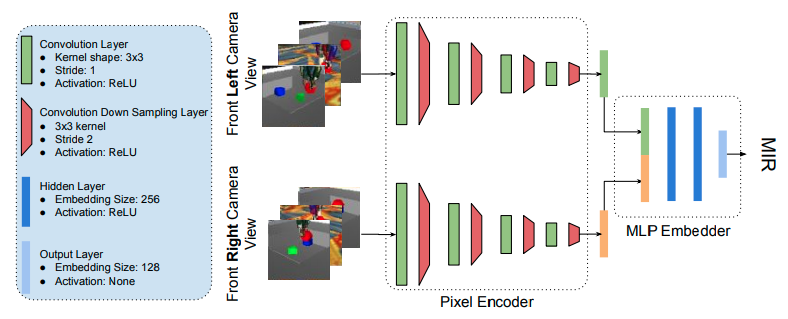
MIRエンコーダは次のようにロボットに取り付けれている2つのカメラ画像を取得する。重みが共有されているCNNは2つの画像をそれぞれ処理し、128チャンネルの特徴量を出力する。2つの特徴量を連結し、MLP EmbedderによりMIRのembeddingを計算する。またCD-GCPで用いる方策は[256, 256, 5]の3層MLPを用いる。
どうやって有効だと検証した?
環境
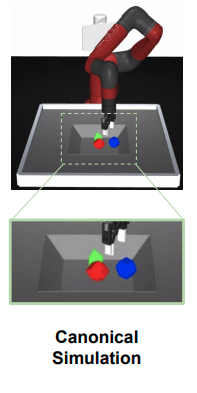
模倣エージェントは常に標準のMuJoCoのシミュレーション環境で動作する。標準の環境は次の3つで構成される。
- SawyerアームとRobotiq 2-finger gripperからなる5自由度マニピュレータ
- バスケットの左右からアーム、物体、バスケットを映す128x128の画像を取得する2つのカメラ
- 3つの幾何学的に異なる物体
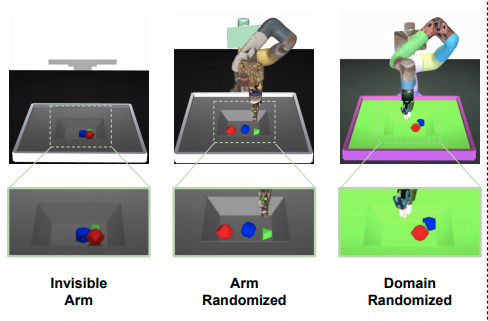
MIR空間を訓練するためのデータを取得する環境は次のとおりである。
- Invisible Arm : マニピュレータをレンダリングから除いた環境
- Arm Randomized : アームの色、テクスチャ、光源、物理特性(質量、摩擦、骨組み、減衰、gear)を変更した環境
- Domain Randomized : すべてのエンティティの色、テクスチャ、光源、物理特性、カメラの位置を変更した環境
cross-embodiment imitationのためのデモンストレーションを生成する環境は次のとおりである。MIR学習には現れない4つのドメインである。
- Jaco Hand : 2-finger Robotiqの代わりに、3-finger Jaco handを使う環境
- Real Robot : 標準のMuJoCoの環境と同等の現実世界の環境
- Pick-up Stick : ロボットアームの代わりに人がスティックをつかって運ぶ現実の環境
- Human Hand : ロボットアームの代わりに人が手で物体を運ぶ現実の環境
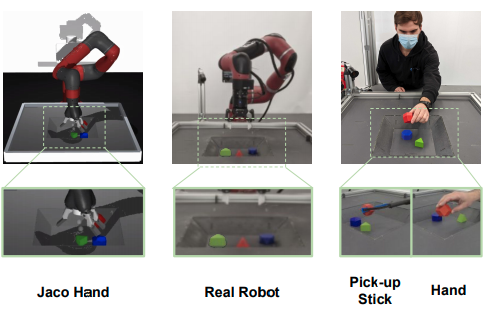
MIR空間の学習データおよびデモンストレーションデータの収集
MIR空間の学習のためにアームを物体のところまで運ぶ、物体をつかむ、持ち上げる、積み上げるなどのバスケットにある3つの物体を使った操作(7194個)のデータを収集した。標準の環境でMaximum a Posteriori Policy Optimization(MPO)により訓練した方策を使った。そしてその方策の操作をInvisible ArmやArm Randomized などの環境で観測して、同じ軌道のビジュアル的に異なるペア(14388個)を作成した。収集したデータの内10792個をMIR空間の訓練に使用し、残りはハイパーパラメータのチューニングに用いた。
Invisible Arm, Jaco Hand, Real Robot, Pick-up StickそしてHuman Handの5つのドメインで作成した。各ドメインにつき各10回のデモンストレーションを行い、Cross-embodiment Imitationに使った。
結果
2つのタスクの成功率を検証した。
- Lifting : 画像から見て一番上にある物体を持ち上げる
- Stacking : 一番上にある物体を一番下ある物体の上にのせる
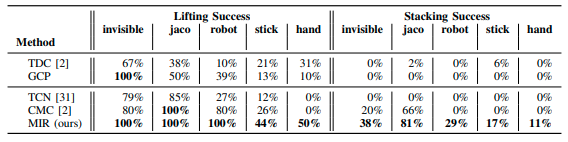
Stackingタスクは3つの物体の内、掴む物体と掴んだ物体をのせる物体を選ぶ操作を必要とする。StackingタスクはLiftingタスクに比べて難しいタスクである。Invisible Arm, Jaco Hand, Real Robot, Pick-up StickそしてHuman Handの5つのドメイン上で100回ずつテストを行い、各ドメインの成功率を検証した。提案するMIRが一番の成功率を示している。
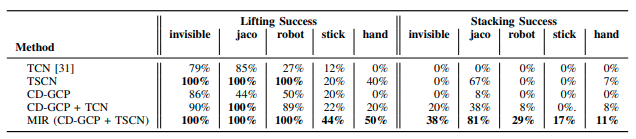
MIRのAblation Studyを行った。MIR(CD-GCPとTSCNの組み合わせ)が最も良いことを示している。
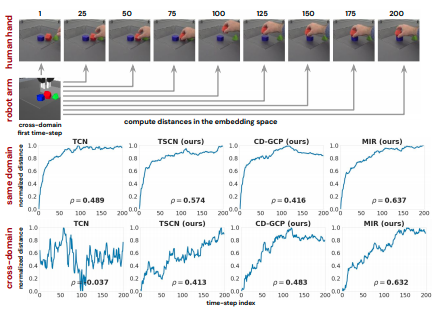
MIR空間上の距離とタスクの進捗率
現在の観測がタスクのゴールからどれだけ距離があるかreachability distanceを直接測ることは難しい。そこで人間の操作を正解として埋め込まれた特徴空間上の距離を計測した。Stackingタスクを行う人のデモンストレーションの各フレームに対して同様の条件に設定したシミュレーション環境の最初のフレームとの距離をMIR空間上で計測した。図中の\(\rho\)はスピアマンの順依存関係数である。提案手法であるSCNやGD-GCP、MIRは異なるドメインでも距離が滑らかに増加しており、タスクの到達可能性との相関性が比較手法のTCNに比べ向上していること示している。
課題は?議論はある?
Coming soon
次に読むべき論文は?
Coming soon
個人的メモ
なし